之前零零散散做过一些数据挖掘比赛,由于个人水平原因和偷懒,要么没坚持下来,要么与得奖失之交臂,也就得过一次小小安慰奖,今天痛改前非,小小记录一下公司内部数据挖掘比赛,算是复盘?
0. 说明
本比赛算是初赛,750人参加,排除掉抄袭后最后名次50+。从开始建模提交次数不算多,中间经过了几次tricks导致分数暴涨,涨到前3后就失去了动力,陷入泥淖。过年疫情那段时间被人疯狂赶上。
1. 探索性数据分析
比赛赛题是“基于用户行为特征分析的骚扰欺诈电话识别”,任务是多分类,评价指标是F1。
数据标签进行了加密,通过hd5解密可以得到真实label。
decode={'7C26FADD409BD4B9':'normal','C7E2941B65C6CCD6':'driver','816A9BEBED2D7C99':'Harassment','0F2E4CC10EDBE80F':'Fraud','56AFA2A526F96CC9'
:'delivery' }
所用可视化的方法来自here作者,原本是二分类的label和features的交叉分析,被我蹩脚的胡改变成多分类,可视化函数如下:
import seaborn as sns
import matplotlib.pyplot as plt
#离散特征
def catPlot_5(data,feature, figsize=(14, 6), save=False, filename=None):#是否正常绘图
df=data.copy(deep=True)
total=len(df)
feature_name = feature.capitalize()
tmp = pd.crosstab(df[feature], df['label'], normalize='index') * 100
tmp = tmp.reset_index()
plt.figure(figsize=figsize)
plt.suptitle(f'{feature_name} Distributions', fontsize=22)
plt.subplot(121)
g = sns.countplot(x=feature, data=df)
# plt.legend(title='Fraud', loc='upper center', labels=['No', 'Yes'])
g.set_title(f"{feature_name} Distribution", fontsize=19)
g.set_xlabel(feature_name, fontsize=17)
g.set_ylabel("Count", fontsize=17)
for p in g.patches:
height = p.get_height()
g.text(p.get_x()+p.get_width()/2.,
height + 3,
'{:1.2f}%'.format(height/total*100),
ha="center", fontsize=14)
plt.subplot(122)
g1 = sns.countplot(x=feature, hue='label', data=df)
#plt.legend(title='label', loc='best', labels=['No', 'Yes'])
gt = g1.twinx()
gt = sns.pointplot(x=feature, y='normal', data=tmp,
color='blue', scale=0.5,
legend=False)
gt = sns.pointplot(x=feature, y='driver', data=tmp,
color='purple', scale=0.5,
legend=False)
gt = sns.pointplot(x=feature, y='delivery', data=tmp,
color='green', scale=0.5,
legend=False)
gt = sns.pointplot(x=feature, y='Harassment', data=tmp,
color='orange', scale=0.5,
legend=False)
gt = sns.pointplot(x=feature, y='Fraud', data=tmp,
color='red', scale=0.5,
legend=False)
#gt.set_ylabel("% of Fraud Transactions", fontsize=16)
#g1.set_title(f"{feature_name} by Target(isFraud)", fontsize=19)
g1.set_xlabel(feature_name, fontsize=17)
g1.set_ylabel("Count", fontsize=17)
plt.subplots_adjust(hspace = 0.6, top = 0.85)
if save:
if filename:
plt.savefig(f'../pics/{filename}.png', bbox_inches='tight', dpi=300)
else:
plt.savefig(f'../pics/{feature_name}.png', bbox_inches='tight', dpi=300)
plt.show()
#连续特征
def distPlot(data,feature, save=False, filename=None):
df=data.dropna()
#df['label']=df['label'].map(lambda x : 1 if x>=3 else 0)
feature_name = feature.capitalize()
g = sns.distplot(df[df['label'] == 'normal'][feature], label='normal')
g = sns.distplot(df[df['label'] == 'driver'][feature], label='driver')
g = sns.distplot(df[df['label'] == 'delivery'][feature], label='delivery')
g = sns.distplot(df[df['label'] == 'Harassment'][feature], label='Harassment')
g = sns.distplot(df[df['label'] == 'Fraud'][feature], label='Fraud')
g.legend()
g.set_title(f"{feature_name} Distribution by Target", fontsize=20)
g.set_xlabel(feature_name, fontsize=18)
g.set_ylabel("Probability", fontsize=18)
if save:
if filename:
plt.savefig(f'../pics/{filename}.png', bbox_inches='tight', dpi=300)
else:
plt.savefig(f'../pics/{feature_name}.png', bbox_inches='tight', dpi=300)
plt.show()
可视化效果如下
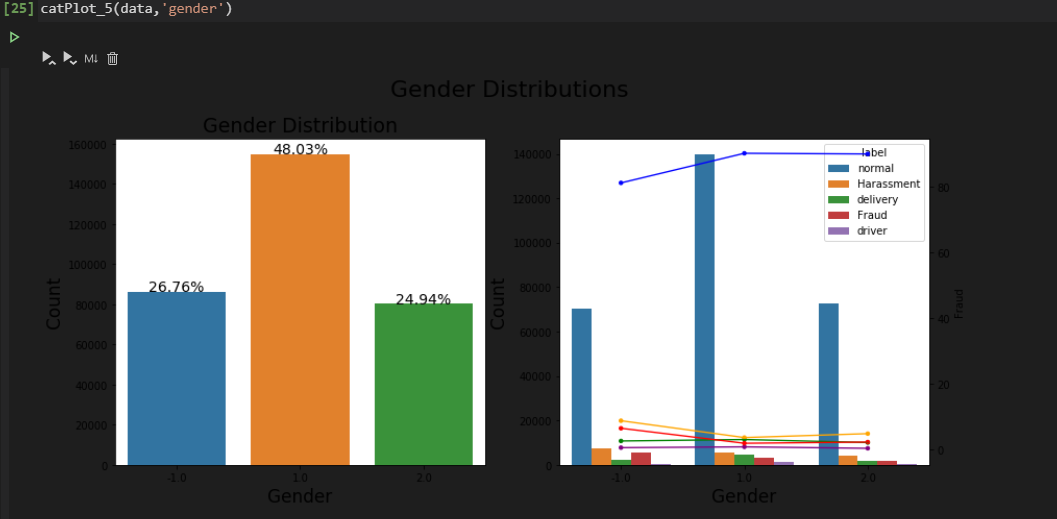
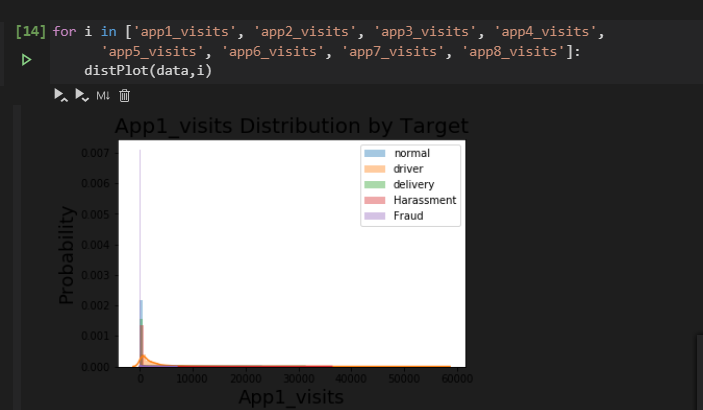
3. 建模思路
经过和同事讨论和排名靠全的同事分享,提高得分的诀窍在于train数据和test数据存在分布差别过大,以及数据不均衡的现象。总结来说tricks有三点,stacking增强模型泛化能力,重采样以及调整损失函数。很遗憾其实我只做到了第二点,简单的将label分布最少的样本翻了一倍;模型集成方面用的相较于stacking更简单的10fold交叉验证,每9折数据建立模型预测pred_prob取平均。
1)特征工程
将缺失值统一插补-9999,取值较少的离散变量,如credit_level,gender,做one-hot处理;用户出生日期这个特征上,将取值个数少于10个的一些取值中,找出一些异常取值(如1911)进行特别标注,产品实例开通日期中,异常取值(如大于20190930)特别标注,CUST_ACCESS_NET_DT客户入网时间,只取到年月日,抛弃小时分钟信息,在网产品个数大于250个统一截断为250。生成特征category_visit,汇总应用启动次数大于0的应用之总启动个数。同时删除特征membership_level会员级别和app1_visits(app1的启动次数),特别是去除后者,对预测得分提升极大,其实算是凑巧发现,我猜可能是在这个特征上train和test差别过大,但在train训练的模型中,此特征的特征重要性却远远甩开同类其他app启动特征的缘故。有些id类特征,如终端厂商,手机终端型号,终端厂商会出现id取值过多,且测试集出现不存在于训练集的id取值这种难搞的现象,这类特征我一直都没有找到好的处理方式,用label做woe编码或者做labelcount编码好像都会透露label信息导致预测精度下降;本次处理方法是先将出现频率小于阈值的取值做统一特殊编码,再做count编码,也就是用特征出现的频数来代替原本取值,最后效果还算不错。其实我感觉这类id特征,一般基于业务去提取主要的信息是最好的,工作量当然也会成倍增加。
总得来说,我还是太不了解移动运营商产品的业务知识了,也找不到人去问,所以生成交叉这方面,还是做的挺贫乏的,
2)建模
没啥好说的,lgb干就完了,10折模型去集成,偷懒代替stacking。
3)样本不均衡
除了把样本量最小的样本数翻了一倍之外,对于多分类预测也采用了阈值调整的方法,效果是非常不错的。
4. 总结
之前总以为比赛只要作好特征工程加调参集成就行,其实并不是,还有更基础的数据层面,在这个坑上面我被折腾了很久,比如训练集和测试集分布过大时要怎么处理,要不要针对数据均衡采取处理,还有一些致命的噪声特征(比如取值全部一样,多个特征高强度相关,train和test分布差别过大),有时候很容易忽视,却是一个降低预测精准度的坑。