目录
第三章 推荐系统冷启动问题
冷启动问题简介
1.用户冷启动 2.物品冷启动3.系统冷启动
解决方法:
1.提供非个性化的推荐如热门排行榜
2.利用用户注册时提供的年龄、性别等数据做粗粒度的个性化。
3.利用用户的社交网络账号登录(需要用户授权),导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品。
4.要求用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些物品相似的物品。
5.对于新加入的物品,可以利用内容信息,将它们推荐给喜欢过和它们相似的物品的用户。
6.在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表。
利用用户注册信息


选择合适的物品启动用户的兴趣
解决用户冷启动问题的另一个方法是在新用户第一次访问推荐系统时,不立即给用户展示推荐结果,而是给用户提供一些物品,让用户反馈他们对这些物品的兴趣,然后根据用户反馈给提供个性化推荐。
启动用户兴趣的物品需要具有以下特点:
1.比较热门
2.具有代表性和区分性
区分度:

3.启动物品集合需要有多样性
Nadav Golbandi的算法:首先会从所有用户中找到具有最高区分度的物品i,然后将用户分成3
类。然后在每类用户中再找到最具区分度的物品,然后将每一类用户又各自分为3类,也就是将
总用户分成9类,然后这样继续下去,最终可以通过对一系列物品的看法将用户进行分类。而在
冷启动时,我们从根节点开始询问用户对该节点物品的看法,然后根据用户的选择将用户放到不
同的分枝,直到进入最后的叶子节点,此时我们就已经对用户的兴趣有了比较清楚的了解,从而
可以开始对用户进行比较准确地个性化推荐。
利用物品的内容信息
tips:,UserCF算法对物品冷启动问题并不非常敏感。因为,UserCF在给用户进行推荐时,会首先找到和用户兴趣相似的一群用户,然后给用户推荐这一群用户喜欢的物品。对于ItemCF算法来说,物品冷启动就是一个严重的问题了。因为ItemCF算法的原理是给用户推荐和他之前喜欢的物品相似的物品。


对物品d,它的内容表示成一个关键词向量如下:
其中, e_i 就是关键词, w_i 是关键词对应的权重。如果物品是文本,我们可以用信息检索领域著
名的TF-IDF公式计算词的权重:

tips:向量空间模型在内容数据丰富时可以获得比较好的效果。以文本为例,如果是计算长文本的相似度,用向量空间模型利用关键词计算相似度已经可以获得很高的精确度。但是,如果文本很短,关键词很少,向量空间模型就很难计算出准确的相似度。
针对物品内容信息的词不同,但含义类似的情况,首先需要知道文章的话题分布,然后才能准确地计算文章的相似度。如何建立文章、话题和关键词的关系是话题模型(topic model)研究的重点。
LDA模型:
LDA作为一种生成模型,对一篇文档产生的过程进行了建模。话题模型的基本思想是,一个人在写一篇文档的时候,会首先想这篇文章要讨论哪些话题,然后思考这些话题应该用什么词描述,从而最终用词写成一篇文章。因此,文章和词之间是通过话题联系的。LDA中有3种元素,即文档、话题和词语。每一篇文档都会表现为词的集合,这称为词袋模型(bag of words)。每个词在一篇文章中属于一个话题。令D为文档集合,D[i]第i篇文档。w[i][j]是第i篇文档中的第j个词。z[i][j]是第i篇文档中第j个词属于的话题。
LDA的计算过程包括初始化和迭代两部分。首先要对z进行初始化,而初始化的方法很简单,假设一共有K个话题,那么对第i篇文章中的第j个词,可以随机给它赋予一个话题。同时,用NWZ(w,z)记录词w被赋予话题z的次数,NZD(z,d)记录文档d中被赋予话题z的词的个数。在初始化之后,要通过迭代使话题的分布收敛到一个合理的分布上去。
在使用LDA计算物品的内容相似度时,我们可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。比如,如果两个物品的话题分布相似,则认为两个物品具有较高的相似度,反之则认为两个物品的相似度较低。计算分布的相似度可以利用KL散度:

发挥专家的作用
专家和机器学习结合进行内容标记。
第四章 利用用户标签数据
基于标签的推荐系统
算法描述:
1.统计每个用户最常用的标签。
2.对于每个标签,统计被打过这个标签次数最多的物品。
3.对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户。

算法的改进:
1.TF-IDF
前面这个公式倾向于给热门标签对应的热门物品很大的权重,因此会造成推荐热门的物品给
用户,从而降低推荐结果的新颖性。
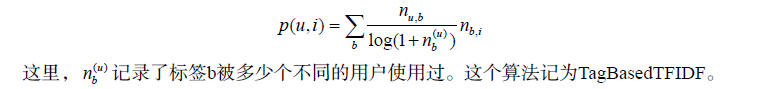

2.数据的稀疏性
在前面的算法中,用户兴趣和物品的联系是通过中的标签建立的。但是,对于新
用户或者新物品,这个集合中的标签数量会很少。
解决方法:进行标签扩展,找到相似的标签。

3.标签清理
1)去除词频很高的停止词;
2)去除因词根不同造成的同义词,比如 recommender system和recommendation system;
3)去除因分隔符造成的同义词,比如 collaborative_filtering和collaborative-filtering 为了控制标签的质量,很多网站也采用了让用户进行反馈的思想,即让用户告诉系统某个标签是否合适。
基于图的推荐算法
我们需要定义3种不同的顶点,即用户顶点、物品顶点和标签顶点.表示用户u给物品i打了标签b的用户标签行为(u,i,b),在定义出用户—物品—标签图后,我们可以用第2章提到的PersonalRank算法计算所有物品节点相对于当前用户节点在图上的相关性,然后按照相关性从大到小的排序,给用户推荐排名最高的N个物品。
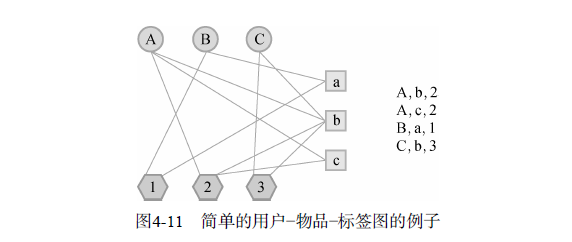
用图模型解释前面的简单算法

给用户推荐标签
如何给用户推荐标签
- 给用户u推荐整个系统里最热门的标签
- 给用户u推荐物品i上最热门的标签
- 给用户u推荐他自己经常使用的标签
- 前面两种的融合(这里记为HybridPopularTags),该方法通过一个系数将上面的推荐结果线性加权,然后生成最终的推荐结果。(在将两个列表线性相加时都将两个列表按最大值做了归一化,这样的好处是便于控制两个列表对最终结果的影响,而不至于因为物品非常热门而淹没用户对推荐结果的影响,或者因为用户非常活跃而淹没物品对推荐结果的影响。)