利用上下文信息
时间上下文信息
时间效应简介
- 用户兴趣是变化的
- 物品也是有生命周期的
- 季节效应
系统时间特性的分析
- 数据集每天独立用户数的增长情况:有些网站处于快速增长期,而有些网站处于平稳期或衰落期。
- 系统的物品变化情况
- 用户访问情况
物品的生存周期和系统的时效性: - 物品平均在线天数
- 相隔T天系统物品流行度向量的平均相似度
推荐系统的实时性
- 实时推荐系统不能每天都给所有用户离线计算推荐结果,然后在线展示昨天计算出来的
结果。所以,要求在每个用户访问推荐系统时,都根据用户这个时间点前的行为实时计
算推荐列表。 - 推荐算法需要平衡考虑用户的近期行为和长期行为,即要让推荐列表反应出用户近期行
为所体现的兴趣变化,又不能让推荐列表完全受用户近期行为的影响,要保证推荐列表
对用户兴趣预测的延续性。
推荐算法的时间多样性
需求:
- 保证推荐系统能够在用户有了新的行为后及时调整推荐结果,使推荐结果满足用户最近的兴趣;
- 需要保证推荐系统在用户没有新的行为时也能够经常变化一下结果,具有一定的时间多样性。
解决方案: - 在生成推荐结果时加入一定的随机性。
- 记录用户每天看到的推荐结果,然后在每天给用户进行推荐时,对他前几天看到过很多次的推荐结果进行适当地降权。
- 每天给用户使用不同的推荐算法。
时间上下文推荐算法
- 最近最热门

- 时间上下文相关的ItemCF算法
算法组成:
- 利用用户行为离线计算物品之间的相似度
- 根据用户的历史行为和物品相似度矩阵,给用户做在线个性化推荐。
时间信息的体现: - 物品相似度:用户在相隔很短的时间内喜欢的物品具有更高相似度。
- 在线推荐:用户近期行为相比用户很久之前的行为,更能体现用户现在的兴趣。

修正预测公式:


- 时间上下文相关的UserCF算法
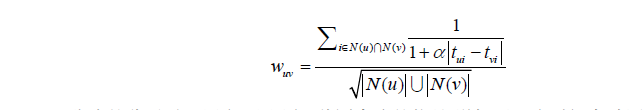

时间段图模型
优化方法:
PersonalRank算法时间复杂度高,提出路径融合算法的方法。
两个相关性比较高的顶点一般具有如下特征:
- 两个顶点之间有很多路径相连;
- 两个顶点之间的路径比较短;
- 个顶点之间的路径不经过出度比较大的顶点。

地点上下文信息
基于位置的推荐算法
数据集有3种不同的形式:
- (用户,用户位置,物品,评分)
- (用户,物品,物品位置,评分)
- (用户,用户位置,物品,物品位置,评分)
用户兴趣和地点相关的两种特征: - 兴趣本地化:不同地方的用户兴趣存在着很大的差别。
- 活动本地化:一个用户往往在附近的地区活动。
针对三种数据集对应的方法:
- 利用用户地理位置的树状结构特点(国家、省、市、县的结构),从根节点出发,在到叶子节点的过程
中,利用每个中间节点上的数据训练出一个推荐模型,然后给用户生成推荐列表。而最终的推荐结果是这一系列推荐列表的加权。 - 物品i在用户u的推荐列表中的权重:
用户u对物品i的兴趣,表示了物品i的位置对用户u的代价,基本思想是对于物品i与用户u之前评分的所有物品的位置计算距离的平均值(如欧式距离)。为了避免计算用户对所有物品的TravelPenalty,LARS在计算用户u对物品i的兴趣度RecScore(u,i)时,首先对用户每一个曾经评过分的物品(一般是餐馆、商店、景点),找到和他距离小于一个阈值d的所有其他物品。
3. 应保证推荐的物品应该距离用户当前位置比较近,在此基础上再通过用户的历史行为给用户推荐离他近且他会感兴趣的物品。
利用社交网络数据
社交网络定义了用户之间的联系,因此可以用图定义社交网络。我们用图定义一个
社交网络,其中V是顶点集合,每个顶点代表一个用户,E是边集合,如果用户和有社交网络
关系,那么就有一条边连接这两个用户,而定义了边的权重。
分类:
- 双向确认的社交网络数据 无向图
- 单向关注的社交网络数据 有向图
- 基于社区的社交网络数据
社交网络数据中的长尾分布
- 社交网络中影响力大的用户总是占少数。
- 而绝大多数用户只关注很少的人。
基于社交网络的推荐
优点
1: 好友推荐可以增加推荐的信任度
2: 社交网络可以解决冷启动问题
基于邻域的社会化推荐算法

基于图的社会化推荐算法
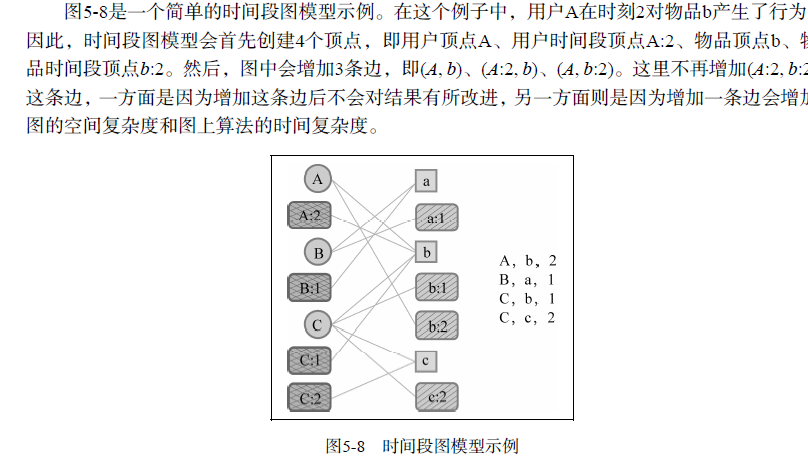
如果用户u对物品i产生过行为,那么两个节点之间就有边相连。比如该图中用户A对物品a、e产生过行为。如果用户u和用户v是好友,那么也会有一条边连接这两个用户,比如该图中用户A就和用户B、D是好友。
在定义完图中的顶点和边后,需要定义边的权重。其中用户和用户之间边的权重可以定义为
用户之间相似度的a 倍(包括熟悉程度和兴趣相似度),而用户和物品之间的权重可以定义为用
户对物品喜欢程度的b 倍。a 和b 需要根据应用的需求确定。如果我们希望用户好友的行为对
推荐结果产生比较大的影响,那么就可以选择比较大的a 。相反,如果我们希望用户的历史行为
对推荐结果产生比较大的影响,就可以选择比较大的b。
定义完顶点、边和边的权重后,就可以利用PersonalRank图排序算法给每个用户生成推荐结果。
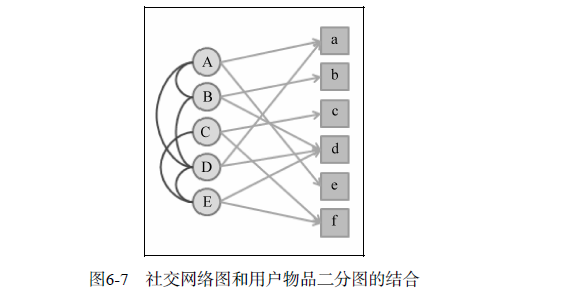
基于社区的社交网络数据推荐方法:
实际系统中的社会化推荐算法
将Twitter的架构搬到社会化推荐系统中,我们就可以按照如下方式设计系统:
- 首先,为每个用户维护一个消息队列,用于存储他的推荐列表;
- 当一个用户喜欢一个物品时,就将(物品ID、用户ID和时间)这条记录写入关注该用户
的推荐列表消息队列中; - 当用户访问推荐系统时,读出他的推荐列表消息队列,对于这个消息队列中的每个物品,
重新计算该物品的权重。计算权重时需要考虑物品在队列中出现的次数,物品对应的用
户和当前用户的熟悉程度、物品的时间戳。同时,计算出每个物品被哪些好友喜欢过,
用这些好友作为物品的推荐解释。
社会化推荐系统和协同过滤推荐系统
社会化推荐系统的效果往往很难通过离线实验评测,1)社会化推荐的优势不在于增加预测准确
度,而是在于通过用户的好友增加用户对推荐结果的信任度,从而让用户单击那些很冷门的推荐
结果。2)很多社交网站(特别是基于社交图谱的社交网站)中具有好友关系的用户并不一定
有相似的兴趣。
信息流推荐
目的:如何从信息墙中挑选有用的评论。虽然我们在选择关注时已经考虑了关注对象和自己兴趣的相似度,但显然我们无法找到和自己兴趣完全一致的人。
Facebook的EdgeRank:
Facebook将其他用户对当前用户信息流中的会话产生过行为的行为称为edge,而一条会话的权重定义为:
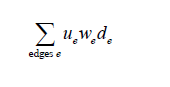
- 指产生行为的用户和当前用户的相似度,这里的相似度主要是在社交网络图中的熟悉度;
- 指行为的权重,这里的行为包括创建、评论、like(喜欢)、打标签等,不同的行为有
不同的权重。 - 指时间衰减参数,越早的行为对权重的影响越低。
EdgeRank算法的个性化因素仅仅是好友的熟悉度,它并没有考虑帖子内容和用户兴趣的相似度。所以EdgeRank仅仅考虑了“我”周围用户的社会化兴趣,而没有重视“我”个人的个性化兴趣。
可考虑如下因素: - 会话的长度
- 话题相关性
- 用户熟悉程度
给用户推荐好友
基于内容的匹配
- 用户人口统计学属性,包括年龄、性别、职业、毕业学校和工作单位等。
- 用户的兴趣,包括用户喜欢的物品和发布过的言论等。
- 用户的位置信息,包括用户的住址、IP地址和邮编等。
基于共同兴趣的好友推荐
用户的协同过滤算法(UserCF),在新浪微博中,可以将微博看做物品,如果两个用户曾经评论或者转发同样的微博,说明他们具有相似的兴趣。此外,也可以根据用户在社交网络中的发言提取用户的兴趣标签,来计算用户的兴趣相似度。
基于社交网络图的好友推荐



