参考资料 Implementing word2vec in PyTorch (skip-gram model).
skip-gram model
1.准备工作
假设我们有一下语料库:
corpus = [
'he is a king',
'she is a queen',
'he is a man',
'she is a woman',
'warsaw is poland capital',
'berlin is germany capital',
'paris is france capital',
]
2.创建词汇表
对每条句子进行分词处理
def tokenize_corpus(corpus):
tokens = [x.split() for x in corpus]
return tokens
tokenized_corpus = tokenize_corpus(corpus)
得到结果为
[['he', 'is', 'a', 'king'],
['she', 'is', 'a', 'queen'],
['he', 'is', 'a', 'man'],
['she', 'is', 'a', 'woman'],
['warsaw', 'is', 'poland', 'capital'],
['berlin', 'is', 'germany', 'capital'],
['paris', 'is', 'france', 'capital']]
然后对单词进行编号:
vocabulary = []
for sentence in tokenized_corpus:
for token in sentence:
if token not in vocabulary:
vocabulary.append(token)
word2idx = {w: idx for (idx, w) in enumerate(vocabulary)}
idx2word = {idx: w for (idx, w) in enumerate(vocabulary)}
vocabulary_size = len(vocabulary)
得到结果
0: 'he',
1: 'is',
2: 'a',
3: 'king',
4: 'she',
5: 'queen',
6: 'man',
7: 'woman',
8: 'warsaw',
9: 'poland',
10: 'capital',
11: 'berlin',
12: 'germany',
13: 'paris',
14: 'france'
然后可以产生中心词(center word), 上下文词(context word)对,假设窗口为2
window_size = 2
idx_pairs = []
# for each sentence
for sentence in tokenized_corpus:
indices = [word2idx[word] for word in sentence]
# for each word, threated as center word
for center_word_pos in range(len(indices)):
# for each window position
for w in range(-window_size, window_size + 1):
context_word_pos = center_word_pos + w
# make soure not jump out sentence
if context_word_pos < 0 or context_word_pos >= len(indices) or center_word_pos == context_word_pos:
continue
context_word_idx = indices[context_word_pos]
idx_pairs.append((indices[center_word_pos], context_word_idx))
idx_pairs = np.array(idx_pairs) # it will be useful to have this as numpy array
得到的结果是
array([[ 0, 1],
[ 0, 2],
...
翻译为:
he is
he a
is he
is a
is king
a he
a is
a king
用图片展示更佳

3.定义目标函数
对于 skip-gram来说,我们感兴趣的概率应该是已知中心词和参数下,上下文词的出现概率,对每一个词对,有
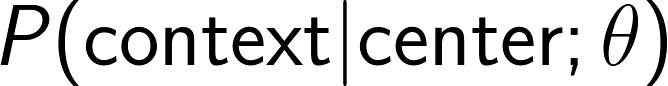
我们的模型,应该能使所有词对的以下概率出现最大化:

为了为方便求导,对目标函数log处理,并求目标函数最小化:
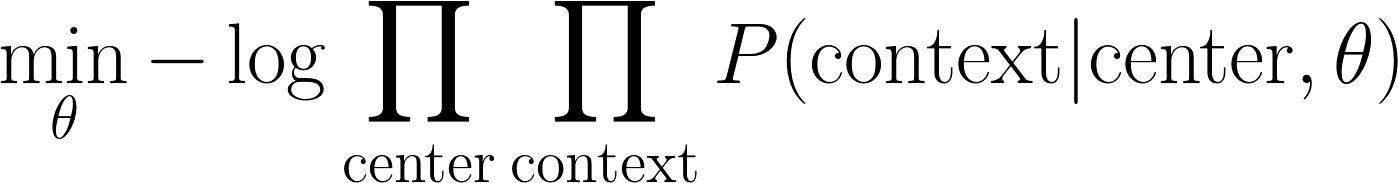
由于,最后的损失函数为:
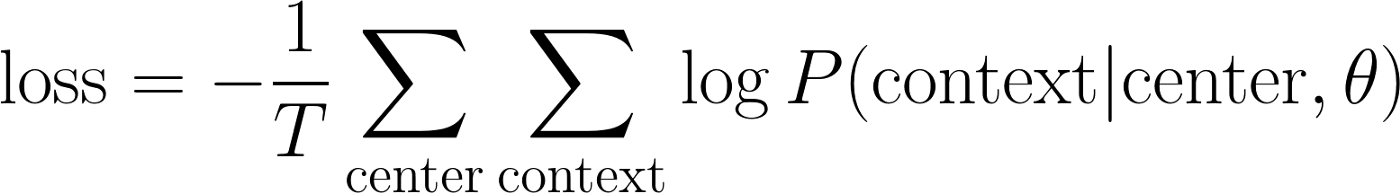
接下来只剩下定义概率P(context|center),可以有
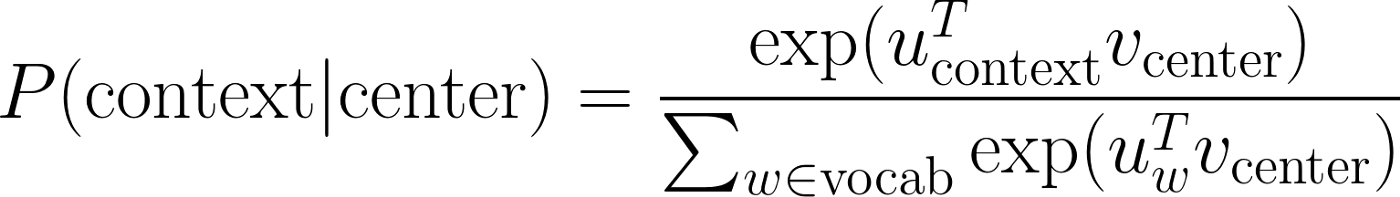
注意其形式类似于softmax函数。
4.coding
Input layer
input layer的作用仅仅是进行one-hot编码
def get_input_layer(word_idx):
x = torch.zeros(vocabulary_size).float()
x[word_idx] = 1.0
return x
Hidden layer
隐藏层实质是输入变量和权重的矩阵乘法
embedding_dims = 5
W1 = Variable(torch.randn(embedding_dims, vocabulary_size).float(), requires_grad=True)
z1 = torch.matmul(W1, x)
W1的每一列都代表着储存着一个单词的词向量。
Output layer
W2 = Variable(torch.randn(vocabulary_size, embedding_dims).float(), requires_grad=True)
z2 = torch.matmul(W2, z1)
最后一层隐藏层有vocabulary_size个神经元,代表着每个单词的出现概率。
输出层:
log_softmax = F.log_softmax(a2, dim=0)
等同于取log后进行softmax的计算效果
最后计算损失函数
loss = F.nll_loss(log_softmax.view(1,-1), y_true)
整体代码如下
embedding_dims = 5
W1 = Variable(torch.randn(embedding_dims, vocabulary_size).float(), requires_grad=True)
W2 = Variable(torch.randn(vocabulary_size, embedding_dims).float(), requires_grad=True)
num_epochs = 100
learning_rate = 0.001
for epo in range(num_epochs):
loss_val = 0
for data, target in idx_pairs:
x = Variable(get_input_layer(data)).float()
y_true = Variable(torch.from_numpy(np.array([target])).long())
z1 = torch.matmul(W1, x)
z2 = torch.matmul(W2, z1)
log_softmax = F.log_softmax(z2, dim=0)
loss = F.nll_loss(log_softmax.view(1,-1), y_true)
loss_val += loss.data[0]
loss.backward()
W1.data -= learning_rate * W1.grad.data
W2.data -= learning_rate * W2.grad.data
W1.grad.data.zero_() #降梯度归0
W2.grad.data.zero_()#降梯度归0
if epo % 10 == 0:
print(f'Loss at epo {epo}: {loss_val/len(idx_pairs)}')
当然在训练word2vec的过程中还有很多工程技巧,比如用negative sampling或Hierarchical Softmax减少词汇空间过大带来的计算量,对高频词汇进行降采样避免对于这些低信息词汇的无谓计算等。